Sparsecat - Moving big files fast
What is sparsecat?
Sparsecat is a tool and Go library created to move sparse files between systems quicker. But what are these sparse files? Sparse files are files that are only partially allocated on the filesystem. Quoting from wikipedia:
In computer science, a sparse file is a type of computer file that attempts to use file system space more efficiently when the file itself is partially empty. This is achieved by writing brief information (metadata) representing the empty blocks to disk instead of the actual “empty” space which makes up the block, using less disk space. The full block size is written to disk as the actual size only when the block contains “real” (non-empty) data.
When reading sparse files, the file system transparently converts metadata representing empty blocks into “real” blocks filled with null bytes at runtime. The application is unaware of this conversion.
See this image below for an example of how that would look on the filesystem:
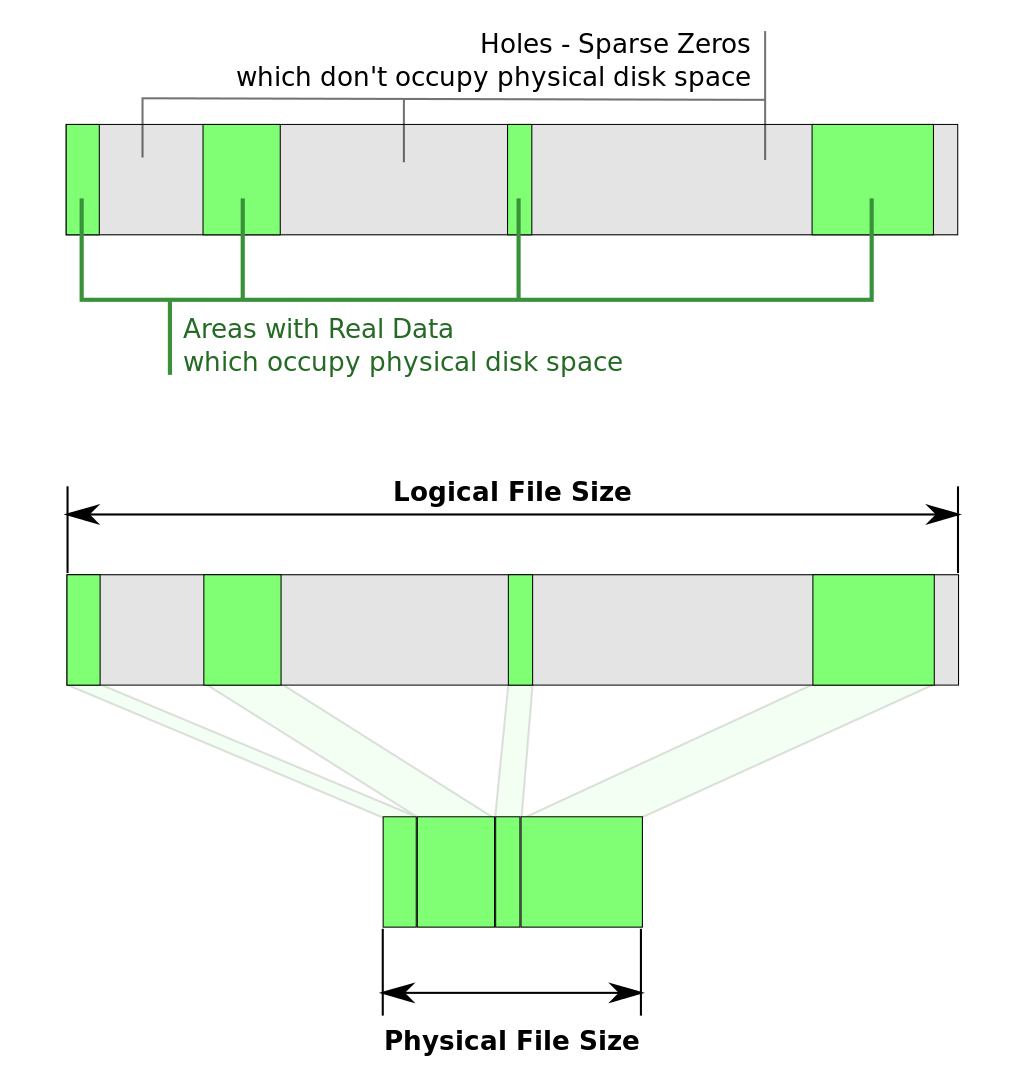
As you can see the physical file size can be much smaller than the virtual one. This makes sparse files very interesting when the files you’re using are mostly empty. An example of such files are the disks of virtual machines, which is our use case. When a virtual machine is created with a disk size of 100GB a one hundred GB sparse file is created and the operating system is installed. After the installation the physical size used could be 5GB. By using sparse files we’ve saved 95GB!
Saving this amount of disk real estate is neat, but there is a catch. Because it is transparent
to normal applications that a file is sparse, meaning they can treat it like any other file, some
operations are slower than they need to be. Copying a file from one system to another using rsync
or a good old cat <file> | ssh <remote machine> pv > <file> is super inefficient. All the blocks
containing no data are transmitted as well. Instead of the 5GB of used space we’re suddenly sending
100 GB, wasting precious bandwidth and time.
An example of this in production is importing a VM image from zfs to ceph. An image is sent to a proxy
server which pipes it to an rbd import command. The rbd command does sparse detection and discards
any empty blocks. As a result the traffic graph of the proxy looks like this:
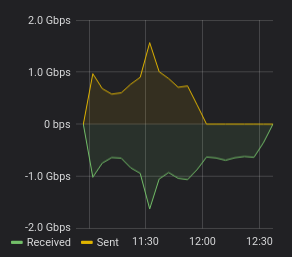
The first part of the graph (until 12:00) shows expected traffic. Data is received from zfs and sent
to ceph. After 12:00 something interesting happens: data is still being received but discarded by
rbd import. If the sparse data was never sent the file transmission could have been 45 minutes faster.
This is where sparsecat steps in. It is able to detect the holes in the file, the parts containing
no data, and skips them. But how does it detect the holes and reconstruct the file?
Hole detection
On linux there is the well known seek syscall, used to seek to an offset from the start of a file or relative to the current position. It does however also have two additional options: SEEK_HOLE and SEEK_DATA. As the names imply SEEK_HOLE allows you to seek to the next position in a file that does not physically exist (a hole) and SEEK_DATA seeks to the next position that does contain data. Using this information we can detect where a section containing data starts and ends. Given a file that is 100 megabytes long and contains data only in the 2nd and 10th megabyte the following sequence of seek calls gives us all the needed information.
| current index | command | output |
|---|---|---|
| 0 | SEEK_DATA | 1048576 (1 megabyte) |
| 1048576 | SEEK_HOLE | 2097152 (2 megabyte |
| 2097152 | SEEK_DATA | 9437184 (9 megabyte) |
| 9437184 | SEEK_HOLE | 10485760 (10 megabyte) |
| 10485760 | SEEK_DATA | ENXIO (no more data) |
Starting at byte index 0 we alternate SEEK_DATA and SEEK_HOLE, giving us the index of the start and end of the data sections: 1048576 - 2097152 and 9437184 - 10485760. This is exactly what the detectDataSection function does and is reflected in an strace of sparsecat:
➜ ~ strace -fff -e trace=lseek sparsecat -if=input.raw >/dev/null
[pid 27599] lseek(3, 0, SEEK_DATA) = 1048576
[pid 27599] lseek(3, 0, SEEK_DATA) = 1048576
[pid 27599] lseek(3, 1048576, SEEK_HOLE) = 2097152
[pid 27599] lseek(3, 1048576, SEEK_SET) = 1048576
[pid 27599] lseek(3, 2097152, SEEK_DATA) = 9437184
[pid 27599] lseek(3, 9437184, SEEK_HOLE) = 10485760
[pid 27599] lseek(3, 9437184, SEEK_SET) = 9437184
[pid 27599] lseek(3, 10485760, SEEK_DATA) = -1 ENXIO (No such device or address)
Wire format
Now that we know what parts of a file we want to transmit we need a wire format that is easy to understand and parse. The main goal of sparscat was to be interoperable with ceph and its rbd import and rbd export-diff commands. Luckily the wire format for rbd is well documented. Each rbd stream starts with a bunch of general information about the incoming image, such as the image size and its name. It also supports sending metadata, but that is beyond the scope of this program. sparsecat only supports three types of sections: the image size, data sections and an end section. Each section is indicated by a letter. At the start of the data stream an s is sent, followed by a 64 bit little endian number containing the image size. From there data sections are created, indicated by a w, followed by the offset of the data in the file, the length of the data and finally the data itself. Once the entire file has been transmitted the stream is finished with a single end marker e.
Reconstructing the file
Reconstructing a file from an incoming stream is a similar process, but backwards. First we receive the size of the incoming image. This allows us to create a sparse file of the correct size right from the start using (*File).Truncate. This notably does not work on windows, which requires some additional setup to enable creating sparse files. After the sparse file has been created each data section can be written to it. This is done by getting the offset and length of the incoming section. (*File).Seek is used to seek to the correct offset and an io.LimitedReader ensures the correct amount of data is copied.
In production
Sparsecat is used as a library for interal tooling that handles sending raw files from zfs to ceph. An example of something similar can be found in the examples directory of the github repository. It has been running in production for a while and has saved a significant amount of data and time. The last 200 jobs using sparsecat have saved around 23 terrabyte, just shy of half the total image size.
Conclusion
Using some neat syscalls data transfers can be significantly sped up. I’ve learned a lot about how the io package of Go is put together, including the fast path optimisation WriteTo method which allows the api surface of the library to remain straightforward. The decoder and encoder can wrap any io.Reader and io.Writer respectively and be used with an ordinary io.Copy call as demonstrated in the examples.